Что такое план аварийного восстановления информационной системы?
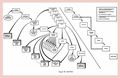
Планом аварийного восстановления информационной системы (Disaster Recovery Plan, DRP) называют документ с руководством по устранению последствий критического сбоя и восстановления данных системы. Кроме того, он содержит список ответственных лиц, которые занимаются восстановлением информационной системы и их обязанности.
Разработка и использование плана позволяет решить следующие задачи организации:
Восстановление IT–инфраструктуры после сбоя или аварии в короткие, но реалистичные сроки.
Обеспечение производительности ведущих функций IT–инфраструктуры на время простоя основного дата–центра.
Сохранение данных системы в допустимом объеме.
Наличие заранее подготовленного плана помогает снизить риски возникновения таких событий, которые могут нанести серьезный урон информационной системе и компании. Каждая организация обязана заботиться о собственной информационной безопасности.
Для этого проводятся различные мероприятия, позволяющие защитить данные от действий злоумышленников. Например, такие, как:
Создание резервных копий в облачных сервисах.
Это позволит сэкономить на оборудовании. Кроме того, поставщики услуг следят за сохранностью и безопасностью серверов, чтобы предоставить гарантии своим клиентам.
Внедрение систем мониторинга и оповещений.
Эти системы проводят постоянную проверку IT–ресурсов организации и находят не только реальные угрозы, но и потенциальные риски, которые требуется устранить. Причем это может быть не только вирус или поломка, но и просто узкие места в коде программы, которые снижают производительность. В случае обнаружения уязвимостей и угроз, система оповещает об этом. Некоторые разработчики даже позаботились о том, чтобы их программа подсказывала возможные варианты решения проблемы.
Внедрение средств для проведения диагностики и анализа.
Они позволяют выявить причину, по которой произошел сбой. Это необходимо для того, чтобы принять в дальнейшем управленческие решения по поводу устранения последствий аварии и предотвращения рецидива.
Внедрение инструментов для восстановления данных.
Они переносят резервные копии из хранилищ с последней обновленной актуальной информацией. То есть в системе восстанавливаются те данные, которые были сохранены до наступления сбоя или аварии. По крайней мере, если этот процесс настроен именно таким образом.
Использование инструментов для управления конфигурацией.
Их применяют для управления изменениями в системе, что дает возможность быстро восстановить конфигурацию после наступления аварии или сбоя.
Использование средств обеспечения отказоустойчивости.
Благодаря им удается продолжать работу с системой, даже если произошла авария. Они используют различные методы, такие как кластеризация или балансировка нагрузки.
Все эти инструменты и методы для создания безопасности вокруг информационной системы важно указать в плане аварийного восстановления, чтобы ответственные лица имели представление о том, с чем им придется работать. Кроме того, необходимо провести обучение всего персонала на случай возникновения внештатной ситуации. В курсе первоначальных мер должны быть даже те, кто не несет ответственность за восстановление информационной системы после сбоя или аварии.
Какие этапы необходимо пройти для создания плана аварийного восстановления системы?
Существует шесть этапов, которые необходимо пройти для создания DRP. Благодаря им получится создать наиболее безопасные условия для информационной системы организации. Ниже рассмотрим каждый из этапов подробнее.
Аудит IT–процессов.
Требования по безопасности программных продуктов в первую очередь зависят от стандартов и законодательства той страны, где разработано ПО. Не менее важную роль играют международные стандарты и ограничения, которые часто выступают в качестве основы для местного законодательства. И лишь потом акцент делается на личных представлениях компании о безопасности и защите данных, которые им требуются для корректной и эффективной деятельности.
Соответственно, аудит подразумевает текущее положение IT–среды, в которой находится настоящий или будущий продукт. В идеале, когда план аварийного восстановления информационной системы составляется до того, как программный продукт вводится в эксплуатацию в компании. Причем неважно, это собственный продукт, заказанный в разработке, либо коробочное решение.
Благодаря аудиту можно понять, соответствуют ли текущие условия безопасности главным стандартам и требованиям отрасли. То есть, по сути, удается заранее обнаружить слабые места, которые нужно улучшить, чтобы сделать информационную систему более защищенной, а значит и защитить данные от действий злоумышленников. ****
Оценка возможных рисков для системы и организации имеет важное значение для дальнейших этапов создания плана аварийного восстановления. Во время анализа специалист должен обратить внимание на три ключевых аспекта, таких как:
Доступность – то есть легко или трудно злоумышленник сможет получить доступ к системе или сети, сколько раз ему придется авторизоваться, какое количество времени на это потребуется и т.д.
Неотвратимость – то есть степень влияния на программу, оборудование и саму организацию. В зависимости от вида атаки и уровня навыков злоумышленников, система может испытать разную уязвимость. В каких–то случаях это будет лишь снижение производительности, а в каких–то полная потеря данных и выведение оборудования из строя. По сути, это тотальный провал информационной системы.
Число компонентов, входящих в состав программно–аппаратного комплекса, которые могут быть подвержено уязвимостям. Кроме того, необходимо оценить, как эти уязвимости могут распространиться между компонентами и влиять на них.
Анализ поможет грамотно рассчитать бюджет, необходимый для того, чтобы при необходимости реализовать DRP.
Разработка DRaaS–решения.
DRaaS – Disaster Recovery as a Service – это облачное решение, которое помогает в срочном порядке восстановить инфраструктуру организации и ее данные в том случае, если происходит отказ локального дата–центра.
С технической точки зрения это удается сделать за счет дублирования данных, которые расположены на серверах компании. Их переносят на облачные серверы провайдера. Преимущественно такая услуга предоставляется на денежной основе в формате подписки. Для расчета тарифа используется план аварийного восстановления информационной системы.
Чтобы проверить эффективность DRP, необходимо полагаться на метрики. Первая из них – целевое время восстановления (RTO), вторая – целевая точка восстановления (RPO). Последняя из них является наиболее важной, так как фокусирует внимание на устойчивости компании к потере данных. То есть, благодаря RPO можно узнать, насколько долго организация будет функционировать без потерянной информации и при этом не иметь экономического ущерба.
Чтобы это рассчитать, необходимо определить время между резервными копиями и объемом данных, которые создаются между резервными копиями и могут быть потеряны. Вторым показателем для расчета является целевое время (RTO), за которое должно быть завершено восстановление данных после сбоя или аварии. Обе метрики являются индивидуальными для каждой отдельно взятой организации, то есть они никогда не будут универсальными.
Значения этих метрик в одной компании будут считаться критичными и указывать на сильный урон, а для другой компании это будет указывать лишь на небольшое снижение производительности. Тут нужно учитывать масштабы бизнеса, его направленность и положение среди конкурентов на рынке.
Этапы плана аварийного восстановления информационной системы
Когда DRaaS разработан, необходимо внедрить его в работу, а также провести тестирование его эффективности. В случае успешной проверки план будет запущен в эксплуатацию.
Внедрение.
Внедрение выбранного решения DRaaS обычно происходит без каких–либо затруднений. В целом, даже не потребуется привлечение каких–либо высококвалифицированных специалистов, которые займутся установкой и настройкой оборудования. Все услуги по внедрению предоставляют облачные провайдеры, которые предоставляют собственных сотрудников. Они обладают необходимыми навыками, опытом и знаниями, чтобы выполнить все необходимые индивидуальные настройки под конкретную организацию. Если потребуется какое–то обучение со стороны заказчика, то с этим также помогут. Обычно такие поставщики облачных услуг предоставляют технический сервис, куда можно обратиться с возникшими вопросами.
Тестирование.
Внедрение решения не дает гарантии, что оно является действительно надежным и работоспособным. Поэтому требуется провести его тестирование, чтобы в этом убедиться. Для этого необходимо рассмотреть следующие задачи:
Осуществить проверку разработанного плана DRP.
Провести анализ проведенных шагов и сохранить их для дальнейшего использования.
Провести проверку решения путем симуляции аварийной ситуации, во время которой зафиксировать полученные показатели. После восстановления работы системы компания сможет снова использовать уже восстановленные данные.
На регулярной основе обновлять план аварийного восстановления. Особенно если бизнес активно масштабируется.
После каждого обновления DRP необходимо проводить повторную проверку.
Запуск в эксплуатацию.
После того, как стратегия плана аварийного восстановления информационной системы прошла все проверки, она будет надежно служить и выполнять свои функции по защите IT–инфраструктуры организации.
Отсутствие DRP делает компанию более уязвимой, так как она не защищена от действий злоумышленников. В случае возникновения сбоя или аварии им потребуется больше времени на то, чтобы выявить причины и устранить последствия, то есть восстановить работоспособность и потерянные данные.
Ежегодно можно наблюдать рост популярности внедрения DRaaS решений, по крайней мере на международном уровне. Это позволяет обеспечить сохранность конфиденциальной информации и защитить бизнес от лишних финансовых рисков.
Какие роли существуют в DRP?
Чтобы обеспечить бесперебойную работу информационной системы и восстановить ее работоспособность в случае возникновения кризиса, требуется группа ответственных лиц. Между ними распределяются роли и обязанности, которые они должны исполнять в форс–мажорной ситуации. Ниже рассмотрим роли, наиболее часто встречающиеся в команде:
Руководитель проекта по DRP.
Самая ответственная должность, так как этот человек занимается разработкой плана аварийного восстановления информационной системы, его внедрением и поддержанием на должном уровне. То есть следит за регулярным обновлением средств защиты системы, чтобы они соответствовали нынешним условиям и требованиям бизнеса.
Руководитель также координирует остальных членов команды, которая отвечает за исполнение DRP. Он ставит задачи специалистам в зависимости от их квалификации и зоны ответственности, а также принимает различные управленческие решения.
Координаторы отделов и подразделений.
Специалисты, которые помогают координировать действия между отделами или даже подразделениями, если компания достаточно масштабна и разрозненна географически. Они могут назначаться на отдельно взятые трудоемкие проекты, которые требуют усиления информационной защиты от атак злоумышленников.
Главной целью координатора является обеспечение согласованности действий членов команды из разных подразделений и отделов в случае возникновения форс–мажорной ситуации, которая наносит урон информационной системе организации.
Системный администратор.
Чтобы план действительно был работоспособным, требуется его техническое обеспечение и сопровождение, которое может предоставить именно системный администратор. Именно он может первым обнаружить сбой и определить его первоисточник. Он принимает активное участие в восстановлении системы и данных, а также помогает в настройке оборудования.
Специалист, отвечающий за информационную безопасность.
Имеет широкий спектр обязанностей, которые включает в себя:
– Разработка мер по предотвращению атак на систему.
– Ищет и оценивает существующие и потенциальные уязвимости, то, как они влияют на производительность системы и какую угрозу несут для компании.
– Анализируют причины возникновения инцидентов в системе, что позволяет предотвратить рецидивы.
Специалист, отвечающий за резервное копирование.
На него возлагается обязанность создания резервных копий данных. Если это происходит автоматически, то следить за тем, чтобы этот процесс проходил корректно. Кроме того, он проводит регулярное обновление средств по защите и восстановлению системы. В случае возникновения инцидента он занимается восстановлением данных либо контролирует автоматический процесс.
Тестировщик и аудитор DRP.
Проверяет инструменты и методы, которые выбраны для плана аварийного восстановления информационной системы. Он тестирует их надежность и работоспособность, чтобы доказать пригодность для защиты данных и системы.
Вышеперечисленные роли могут быть совмещены в одном специалисте или существовать по отдельности в зависимости от масштабов компании и сложности ее структуры. Равномерное распределение обязанностей позволит снизить риск влияния человеческого фактора. Кроме того, поставщики DSaaS позволяют снять часть ответственности с сотрудников компании за счет автоматизации многих задач.
DSaaS решения для плана аварийного восстановления информационной системы?
Все большее количество облачных провайдеров предлагают восстановление как услуга (DSaaS). Рассмотрим ТОП-3 поставщиков облачных услуг по итогам 2023 года в России.
Облачный бизнес МТС.
Является одним из крупнейших поставщиков облачных услуг, который предоставляет широкий набор инструментов для бизнеса. Имеет в своем арсенале частные, общие и гибридные форматы облака, что позволяет использовать возможности провайдера компаниям с разными финансовыми возможностями. Обладают собственным оборудованием, размещенным в дата–центрах уровня TIER III в таких городах, как Москва, Санкт–Петербург, Новосибирск, Владивосток, а также за пределами страны в Минске, Алмате и Ереване.
Softline.
Основными направлениями работы являются: миграция данных и их защита, а также управление облачной инфраструктурой. Они предлагают множество различных инструментов для автоматизации бизнес–процессов и разработки, в том числе и автоматическое резервное копирование информации в организации. Поставщик постоянно работает над инновационными решениями, поэтому может предложить не только надежность, но и передовые технологии.
mClouds.
В качестве базы сервиса взята платформа Veeam Backup&Replication. Она позволяет обеспечить надежность системы и ее комплексную защиту. Они предлагают резервное копирование любого объема данных: от обычного файла до целой системы. Причем они придерживаются быстрой концепции, что позволяет бизнесу быстрее обезопасить себя и свои данные.
Каждый из облачных провайдеров может предложить свои тарифы согласно тем услугам, которые они предоставляют, и тем потребностям, которые имеет клиент. На рынке, в целом, нет дефицита облачных услуг, поэтому выбрать есть из чего.

 Телеграм
Телеграм