Понятие инцидентов и ITIL
Для начала дадим определение ITIL (Information Technology Infrastructure Library) – это фреймворк, который содержит в себе лучшие и проверенные практики для управления ИТ–технологиями и сервисами. Его разработали в конце 1980-х годов в Великобритании для оптимизации работы ИТ–продуктов, повышения их качества и эффективности.
ITIL имеет ряд преимуществ для внедрения в работу компании:
Способствует тому, чтобы ИТ–услуги совпадали с бизнес–целями и помогали организации добиться успеха.
Помогает следить за расходами на ИТ и оптимизировать их.
Дает возможность улучшить сервис компании и повысить уровень удовлетворенности клиентов.
Позволяет сохранять гибкость и быстро адаптироваться к новым условиям на рынке за счет быстрого внедрения готовых решений из библиотеки.
Повышает ценность выпускаемой продукции и услуги.
Теперь разберем понятие инцидентов.
В ИТ–сфере под этим понимается ситуация, которая нарушает стабильную работу бизнеса, каким–либо образом тормозит ее или вовсе останавливает. Это могут быть сбои в работе виртуального облака или сервера, утечка конфиденциальных данных, баги и прочее.
Управление ИТ–инцидентами – это деятельность, направленная на устранение проблем в работе ИТ–служб за определенный период времени, который указан в рамках соглашения об уровне сервиса (SLA). Он заключается между заказчиками услуг и их поставщиком. Например, такой договор может заключаться в сфере обслуживания оборудования, которое работает с помощью специального программного обеспечения. Оно бывает в физическом бумажном виде или в электронном.
Существует множество критериев по которым можно классифицировать ИТ–инциденты. Среди них такие, как:
Продолжительность.
То есть то время, которое требуется на устранение возникшей проблемы. Они могут быть как краткосрочные, так и долгосрочные. В первом случае и трудозатраты будут меньше, и расходы ресурсов тоже. Во втором случае устранение проблемы и восстановление работоспособности ИТ–службы может потребовать некоторого времени и возможно даже вложения средств.
По типу источника.
Здесь разделение идет на внутренние и внешние инциденты. Первые происходят внутри организации, могут быть связаны непосредственно с деятельностью компании. Например, утечка важной коммерческой информации. Вторые возникают во внешней среде, на которые, обычно либо очень сложно влиять, либо вообще невозможно. Это могут быть катаклизмы, которые оборвали линии передач сети, или сбой сервера.
По характеру воздействия.
Тут возникновение инцидента может происходить по технической причине или из–за воздействия человеческого фактора. Например, техника может выйти из строя по разным причинам. Это может произойти из–за нарушений условий эксплуатации или просто по истечению срока использования. В другом случае причиной может стать человеческая неосторожность, если в результате ремонта повредить кабель питания.
По интенсивности воздействия.
То есть здесь учитывается то, какое количество людей было вовлечено в ИТ–инцидент. Те или тот, кто обнаружил, + те, или тот, кто устранил. Также могут быть посредники в виде руководящего звена. Например, если старый рабочий компьютер вышел из строя, то в процесс будут вовлечены:
сотрудник, который это обнаружил;
руководитель, которому поступило сообщение о поломке;
бухгалтер, который выделил средства из бюджета на покупку нового оборудования по распоряжению начальства;
технический специалист/сисадмин, который осуществляет покупку и установку нового оборудования.
Инцидент отличается от проблемы тем, что обычно не занимает много времени для его устранения. Проблема же является более обширным понятием и охватывает разные аспекты от поиска источника и до устранения последствий. Например, если компьютер на рабочем месте не включается по причине того, что произошли перебои электроэнергии, то это инцидент. Но если из–за этого не удалось выполнить важную задачу для заказчика, то это уже проблема.
Другим примером может служить ситуация, когда компания использует виртуальное облако для хранения документации и прочих файлов. Оно постоянно переполняется, что тормозит работу сотрудников. Копирайтер не может сохранить текст – это инцидент. Недостаток виртуального пространства для хранения – это проблема. Решением в таком случае будет увеличение объема памяти.
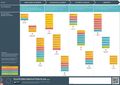
Жизненный цикл управления инцидентами
Процесс управления ИТ–инцидентами условно можно разделить на несколько ключевых этапов, которые будут встречаться практически в каждом случае.
1 этап: Обнаружение инцидента и оповещение о нем.
Сотрудник, который обнаружил инцидент и не может устранить его самостоятельно, должен оповестить об этом системного администратора или команду техподдержки SLA. Это осуществляется через различные инструменты коммуникации или управления, будь то Jira, ICQ, SMS, Trello и другие. В гибких методах управления, таких как, например, Kanban используются специальные доски.
Зафиксировать информацию об инциденте необходимо по нескольким причинам. Во–первых, чтобы банально не забыть. Сотрудник указывает на тот фактор, который тормозит работу. Во–вторых, это позволяет найти скрытую проблему, из–за которой и возникают такие инциденты. Например, команда часто регистрирует инцидент с отключением интернета, который возникает в разное время. Причиной может быть то, что рядом с линией передач растет дерево. Во время порывов ветра ветки затрагивают кабель и поэтому пропадает связь. Чтобы инциденты больше не повторялись, ветки с этой стороны обрезаются.
В дальнейшем, если сеть будет обрываться, то уже по другим причинам, которые уже потребуется найти.
2 этап: Классификация инцидента и присвоение приоритета.
После того, как инцидент был обнаружен и зафиксирован, его требуется классифицировать. Это необходимо для того, чтобы можно было определить приоритетность данной задачи для ее решения. Если инцидент влияет на рабочий процесс в значительной мере, то техподдержка будет устранять инцидент в скором порядке.
Например, если на кассе не проходит оплата картой, то этот вопрос можно решить перезапуском терминала. С этой задачей может справиться и кассир. Однако, если зависла сама программа, которая ведет учет продаж, то этот инцидент уже может решить только системный администратор. Если наладка не происходит долго, то это уже принимает статус проблемы, так как она сильно тормозит рабочий процесс и влияет на уровень удовлетворенности клиентов.
3 этап: Маршрутизация и создание задачи.
Тут ключевую роль играют два важных фактора. Во–первых, сама суть инцидента, ее классификация и приоритетность. Во–вторых, структура компании и ее возможности. В некоторых случаях устранение инцидентов возлагается на штатных сотрудников, например, системных администраторов. Они могут устранить какие–то внутренние сбои и баги. Банально просто перезапустить роутер, если вдруг не удается зайти на какой–то сервис из–за разрыва в соединении.
Если компания достаточно крупная, то она будет иметь целый ИТ–отдел, который будет заниматься всеми вопросами, связанными с ИТ. Это и работа серверов, и настройка программ, и устранение сбоев, и т.д.
Другие компании, которые не видят смысла на постоянной основе держать сотрудника по ИТ, пользуются услугами аутсорсеров. Некоторые системные администраторы сотрудничают сразу с несколькими организациями, пишут для них программы, дополняют их, устраняют баги, проводят тестирование и т.д.
4 этап: Работа над задачей и ее завершение.
После того, как инцидент классифицирован и определена его приоритетность, назначается ответственное лицо, которое будет заниматься решением данной задачи. Этот специалист определяет время, необходимое для устранения инцидента. После чего он выполняет необходимые работы, а затем меняет статус задачи на «Исполнено».
Все этапы жизненного цикла выполняются в соответствии с условиями SLA.
Кто управляет инцидентами?
Для управления инцидентами могут назначаться разные специалисты. Эти роли могут назначаться как внутри компании, так и за ее пределами. В ИТ–сфере существует несколько участников, которые занимаются работой с инцидентами. Среди них такие, как:
Конечный пользователь.
Обычно он же и выступает в качестве персоны, которая заявляет о случившемся инциденте. В целом это может быть любое заинтересованное лицо, чьи интересы заключаются в том, чтобы поддерживать работоспособность компании и оптимизировать процессы для улучшения эффективности.
Его зоной ответственности является оповещение соответствующих лиц о произошедшем инциденте, точно и четко объяснить случившуюся ситуацию. Кроме того, он контролирует исполнение задачи по устранению инцидента и докладывает руководству/отмечает в системе о ее завершении.
1 уровень службы поддержки.
Обычно под эту категорию подходят технические специалисты, обладающие ключевыми знаниями в области ИТ. Они устраняют самые распространенные и легкие инциденты. Например, осуществляют сброс пароля в учетной записи, настраивают работу принтера, подключают оборудование компьютера для нового сотрудника и прочее.
Их зона ответственности самая узкая, но не менее важная. Они принимают заявки от конечных пользователей, проводят их регистрацию, классификацию и назначают уровень приоритетности. В случае, если специалист не обладает должной квалификацией, то он производит эскалацию задачи до 2 уровня. Он также участвует в контроле решения задачи по устранению инцидента.
2 и 3 уровень службы поддержки.
Эта категория специалистов, которые имеют более высокую квалификацию и более глубокие познания в устранении инцидентов. Они также могут быть разделены по профессиям в зависимости от своей специализации.
Ответственность данного уровня техподдержки заключается в том, что они документируют действия, которые были предприняты для решения задачи. Они проводят диагностику инцидента, чтобы затем определить его как проблему и подать заявку на устранение проблемы, а не инцидента.
Кроме того, они могут предоставить свои экспертные знания и опыт для дальнейшего управления возникшей проблемой.
Инцидент–менеджер.
Занимается управлением инцидентов на более высоком и сложном уровне. Он проводит мониторинг, предоставляет рекомендации по решению задачи и проводит координацию,а также дает оценку эффективности предпринятых действий.
Кроме того, этот специалист обеспечивает соответствия требованиям SLA, так как является одним из самых квалифицированных участников в цепочке устранения инцидента.
Ответственный за инциденты.
Осуществляет предотвращение инцидентов. Разрабатывает для этого эффективные меры и контролирует их исполнение и соблюдение. Когда возникают инциденты, то полностью контролирует и координирует весь процесс от и до. По сути выступает в роли верховной инстанции в самых сложных ситуациях.
Так же на него возлагается определение ключевых показателей эффективности. Он осуществляет оценку проделанной работы, чтобы обеспечить соответствие бизнес–задачам компании.
Разрабатывает стандарты, методы и рекомендации по оптимизации процессов.
Распределяет роли и их зону ответственности в управлении инцидентами.
Следит за изменениями в отрасли, чтобы меры по устранению инцидентов происходили в соответствии с актуальными стандартами.
То, как будут распределяться роли в процессе управления инцидентами, определяется множеством факторов. Не каждая компания имеет возможности работать с целой командой специалистов, которые занимаются решением подобных задач. В целом достаточно часто в реальности ответственность за управление инцидентами возлагается на 1-2 человека, которые совмещают в себе несколько ролей. А верхушкой цепочки является руководитель компании–заказчика.
Главные показатели эффективности управления инцидентами
Управление инцидентами с помощью ITIL несет для бизнеса ряд преимуществ. Например, таких как:
Благодаря внедрению системы управления ИТ–инцидентами, компания имеет возможность улучшить свои рабочие процессы. Это повысит уровень удовлетворенности клиентов, а также позволит снизить некоторые операционные расходы.
Кроме того, предотвращение и устранение инцидентов позволяет избежать более сложных проблем и их последствий.
Также не стоит забывать о том, что данные о случившихся инцидентах документируются в общем репозитории, поэтому их можно использовать в случае рецидива.
ITIL дает возможность автоматизировать процесс классификации инцидента, присвоения ему степени приоритизации и назначения ответственного лица по решению задачи по устранению.
Управлением и устранением сложностей занимаются узкоспециализированные сотрудники с определенными навыками, знаниями и опытом, необходимыми для этого. Соответственно снижается риск влияния человеческого фактора, когда устранением инцидента занимается специалист без должной квалификации. Кроме того, таким образом соблюдается техника безопасности.
ITIL хранит всю информацию по полученному опыту, а значит его можно использовать для отчетности или обучения.
Для оценки деятельности по управлению инцидентами используются коэффициенты эффективности. Они необходимы для того, чтобы ответственное лицо могло принять соответствующие меры в том случае, если инцидент перешел в статус проблемы, либо произошло отклонение от стандартов SLA.
К показателям коэффициентов эффективности относятся:
Среднее время ответа – временной показатель, который указывает на то, насколько оперативно осуществляется техническая поддержка.
Среднее время принятия решения – ещё один временной показатель, позволяющий понять степень сложности инцидента, как быстро можно решить задачу по его устранению. Эту метрику можно использовать не только для оценки текущей эффективности, но и для планирования работы и KPI сотрудников.
Процент соответствия SLA – соотношение числа ИТ–инцидентов, которые были решены в соответствии с установленными стандартами соглашения об уровне предоставляемых услуг.
Процент оперативности принятия решений – соотношение быстро принятых решений, выраженное в процентах. Таким образом удается посчитать, какое количество инцидентов от общего числа было устранено оперативно.
Количество повторных инцидентов – указывает на то, как часто повторялся один и тот же инцидент за определенный период времени. Таким образом можно вычислить скрытую проблему.
Процент повторных открытий – показывает, в процентном соотношении в каком количестве решенные инциденты были открыты вновь. Так можно определить, что, вероятно, ранее предпринятые меры не были эффективными. Тогда инцидент могут классифицировать как проблему и определить других специалистов и другой порядок действий по ее устранению.
Невыполненная работа по инцидентам – отражает, какое количество инцидентов ещё находятся в работе и не получили решение. Этот показатель может указывать на продуктивность сотрудника или команды.
Процент серьезных инцидентов – с ее помощью можно вычислить, какой процент серьезных инцидентов от общего числа инцидентов. Это может указывать и на скрытые проблемы, и на эффективность работы сотрудника или команды.
Стоимость одной заявки – средний размер расходов на выполнение одной заявки. Помогает при принятии решений, управлении бюджетом и для составления отчетов.
Уровень удовлетворенности конечного пользователя – число конечных пользователей или клиентов компании–заказчика, которые удовлетворены предоставленными ИТ–услугами. Чем этот показатель выше, тем лучше исполнитель справляется со своими обязанностями по управлению инцидентами.

 Телеграм
Телеграм